---
title: "Aufgaben zu Konfidenzintervallen in verschiedenen Szenarien"
subtitle: "Lösungsvorschläge – Wahrscheinlichkeitsrechnung und Statistik (WS_PiBS)"
title-block-banner: ./images/ffhs-farbwelt-verlauf_01.jpg
lang: de
format:
html:
logo: ./images/FFHS_Logo.png
include-in-header:
text: |
<style>
.title { color: white !important; }
.subtitle { color: white !important; }
.quarto-title-banner .quarto-title {
padding-left: 160px;
}
</style>
<script>
document.addEventListener('DOMContentLoaded', function () {
var banner = document.querySelector('.quarto-title-banner');
if (banner) {
banner.style.position = 'relative';
var logo = document.createElement('img');
logo.src = './images/FFHS_Logo.png';
logo.style.cssText = [
'position: absolute',
'left: 0px',
'top: 45%',
'transform: translateY(-50%)',
'height: 90px',
'width: auto',
'z-index: 10',
'filter: brightness(0) invert(1)'
].join(';');
banner.insertBefore(logo, banner.firstChild);
}
});
</script>
theme: cosmo
toc: true
toc-title: "Inhaltsverzeichnis"
toc-depth: 4
toc-location: right
code-fold: true
code-tools: true
embeded-sources: false
execute:
warning: false
message: false
editor:
markdown:
wrap: sentence
---
```{r}
#| code-fold: true
#| label: setup
library(tidyverse)
library(patchwork)
blau <- "#2C7BB6"
rot <- "#D7191C"
grau <- "grey50"
# Datensätze für Aufgaben 5–8
app_absturzrate <- read_csv("data/app_absturzrate.csv")
produktionsfehler <- read_csv("data/produktionsfehler.csv")
kundenzufriedenheit <- read_csv("data/kundenzufriedenheit.csv")
serverausfall <- read_csv("data/serverausfall.csv")
```
------------------------------------------------------------------------
## Aufgabe 1: Akkus
Eine Firma stellt Akkus her.
Die Anzahl Lade-/Entladezyklen, bis ein solcher Akku nur noch 60% seiner ursprünglichen Ladekapazität erreicht, ist in einer Stichprobe von 10 Akkus annähernd normalverteilt mit Mittelwert $\bar{x} = 475$ und Varianz $\text{Var}(x) = 1000$.\
a) Bestimmen Sie das 90%-Konfidenzintervall für die mittlere Anzahl Lade-/Entladezyklen, bis ein Akku aus der Gesamtproduktion nur noch 60% seiner ursprünglichen Ladekapazität erreicht.\
b) Ein potentieller Abnehmer verlangt, dass die Akkus im Mittel mindestens 500 Lade-/Entladezyklen überstehen, bis die Akkus nur noch 60% der ursprünglichen Kapazität erreichen.
Erfüllen die Akkus der Firma diese Bedingung auf Grund des in a) bestimmten 90%-Konfidenzintervalles?\
c) Die Firma argumentiert, dass die Verwendung eines 90%-Konfidenzintervalles unfair sei und dass bei einem 95%-Konfidenzintervall die Chance zur Erfüllung der Bedingung grundsätzlich grösser sei.
Hat die Firma recht?
::: {.callout-tip title="Analytische Lösung anzeigen" collapse="true"}
a. **90%-Konfidenzintervall bestimmen**
Da die Varianz der Grundgesamtheit **nicht** bekannt ist, verwenden wir die t-Verteilung:
Gegeben:
- $n = 10$
- $\overline{x} = 475$
- $s^2 = 1000 \Rightarrow s = \sqrt{1000}$
- $\alpha = 0.10 \Rightarrow \frac{\alpha}{2} = 0.05$ (beidseitig symmetrisch)
- $df = n - 1 = 9$
Standardfehler: $SE = \frac{s}{\sqrt{n}} = \frac{\sqrt{1000}}{\sqrt{10}}=10$
t-Wert: $$ t_{(0.95, 9)} \approx 1.833 $$
Konfidenzintervall: $$\text{90\%-KI:}\quad \overline{x} \pm t \cdot SE = 475 \pm 1.833 \cdot 10 = [456.67, 493.33] $$
b. Vergleich mit Anforderung von mindestens 500 Zyklen
Da das gesamte Intervall unter 500 liegt, wird die Anforderung **nicht erfällt**.
c. Ist ein 95%-KI günstiger?
t-Wert: $$ t_{0.975, 9} \approx 2.262157 $$ Konfidenzintervall: $$\text{95\%-KI:}\quad \overline{x} \pm t \cdot SE = 475 \pm 2.262 \cdot 10 = [452.38, 497.62] $$Das 95%-KI ist breiter, aber die Obergrenze des KIs ist immer noch kleiner als 500.
Also **nicht günstiger für die Firma**.
:::
::: {.callout-tip title="Lösung mit R anzeigen" collapse="true"}
```{r}
n <- 10
xbar <- 475
s2 <- 1000
s <- sqrt(s2)
df <- n - 1
# 90%-KI
alpha_90 <- 0.10
t_crit_90 <- qt(1 - alpha_90 / 2, df)
SE <- s / sqrt(n)
ME_90 <- t_crit_90 * SE
KI_90 <- c(xbar - ME_90, xbar + ME_90)
# 95%-KI
alpha_95 <- 0.05
t_crit_95 <- qt(1 - alpha_95 / 2, df)
ME_95 <- t_crit_95 * SE
KI_95 <- c(xbar - ME_95, xbar + ME_95)
sprintf("90%%-Konfidenzintervall: [%.2f, %.2f]", KI_90[1], KI_90[2])
sprintf("95%%-Konfidenzintervall: [%.2f, %.2f]", KI_95[1], KI_95[2])
```
:::
------------------------------------------------------------------------
## Aufgabe 2: Materiallager
Im automatisierten Materiallager einer grossen Firma beträgt momentan die mittlere Auslieferungszeit für einen umfangreichen Auftrag t = 32 Minuten.
Nun soll das Materiallager reorganisiert werden, so dass die Auslieferungszeiten kürzer werden.
Dazu stehen nach einigen Vorabklärungen schliesslich zwei verschiedene Varianten zur Verfügung.
Diese beiden Varianten werden mit Hilfe von mehreren, aufwendigen Simulationen getestet, in welchen die Auslieferungszeiten für verschiedene, umfangreiche Aufträge erfasst werden.
In Variante 1 ergibt sich bei 17 Simulationen für die Auslieferungszeit ein arithmetisches Mittel von t = 29 Minuten bei einer Standardabweichung von $s_1$ = 8 Minuten.
In Variante 2 ergibt sich bei 15 Simulationen für die Auslieferungszeit ein arithmetisches Mittel von t = 30 Minuten bei einer Standardabweichung von $s_2$ = 5 Minuten.
Es wird angenommen, dass in beiden Varianten die Auslieferungszeiten normalverteilt sind.
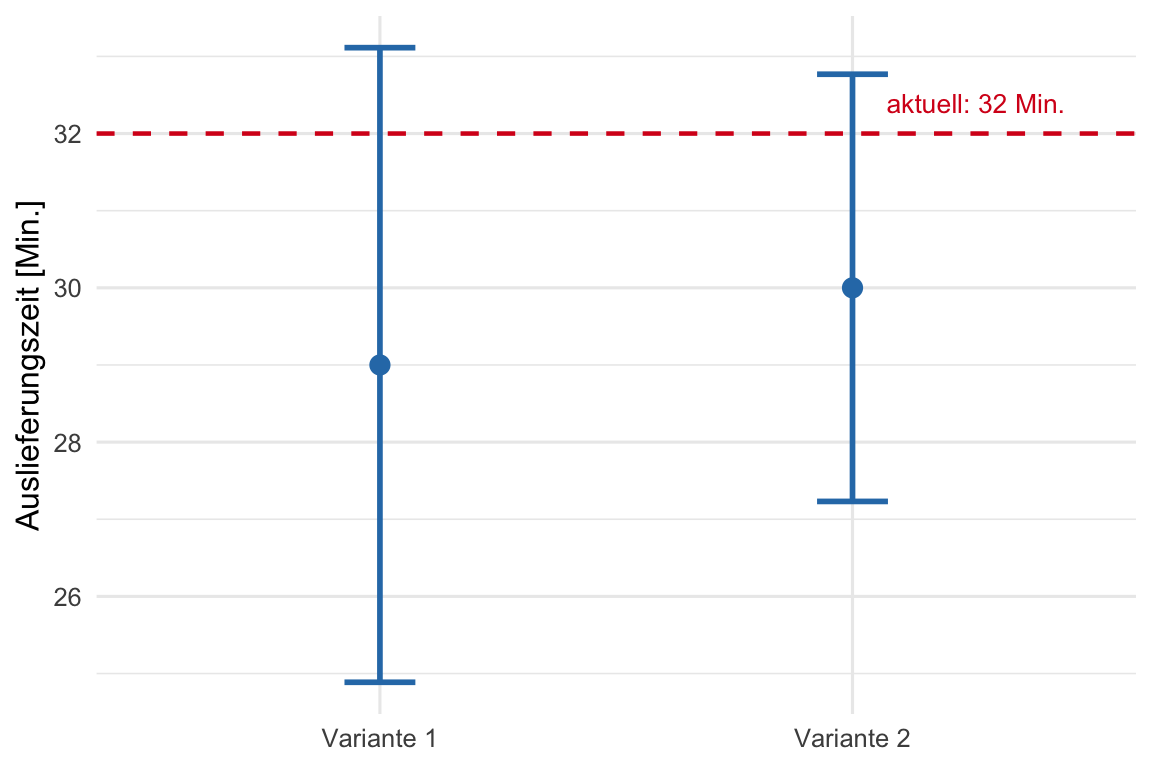
Klären Sie mit Hilfe von geeigneten Konfidenzintervallen auf dem 95%-Vertrauensniveau ab, ob (mindestens) eine der beiden Varianten die Auslieferungszeit voraussichtlich senkt.
::: {.callout-tip title="Analytische Lösung anzeigen" collapse="true"}
Da die Standardabweichung der Grundgesamtheit **unbekannt** ist, verwenden wir wieder die t-Verteilung.
**Variante 1:**
$\overline{x}_1 = 29$, $s_1 = 8$, $n_1 = 17$, $df_1 = 17-1=16$
$$SE_1 = \frac{8}{\sqrt{17}} \approx 1.94$$
$$ t_{(0.975, 16)} \approx 2.120 $$
$$ KI_1 = 29 \pm 2.120 \cdot 1.94 \approx [24.89, 33.11] $$
**Variante 2:**
$\overline{x}_2 = 30$, $s_2 = 5$, $n_2 = 15$, $df_2 = 14$
$$ SE_2 = \frac{5}{\sqrt{15}} \approx 1.29 $$
$$ t_{(0.975, 14)} \approx 2.145 $$
$$ KI_2 = 30 \pm 2.145 \cdot 1.29 \approx [27.23, 32.77] $$
**Interpretation:**
Bei beiden Varianten ist der ursprüngliche Wert von $t=32$ Min. in den KIs enthalten.
Zwar ist das KI der Variante 2 kürzer - und damit mit weniger Unsicherheit verbunden-, aber der Mittelwert der Stichprobe liegt auch höher als bei Variante 1.
Bei dieser ist das KI deutlich länger - und damit unsicherer- aber der Mittelwert liegt tiefer.
Damit ist es gesamthaft schwierig eine klare Entscheidung zu treffen.
**Keine** Variante überzeugt, dass sie mit hoher Zuverlässigkeit niedrigere Auslieferzeiten liefern wird.
Es wäre zu empfehlen für Variante 1 mehr Simulationen durchzuführen um zusehen, wie sich dann der Mittelwert der Stichprobe entwickelt.
Bleibt er bei dieser Zeit und das KI wird kürzer, sollte man Variante 1 wählen.
:::
::: {.callout-tip title="Lösung mit R anzeigen" collapse="true"}
```{r}
xbar1 <- 29; s1 <- 8; n1 <- 17
xbar2 <- 30; s2 <- 5; n2 <- 15
alpha <- 0.05
# Variante 1
df1 <- n1 - 1
t_crit1 <- qt(1 - alpha/2, df1)
ME1 <- t_crit1 * s1 / sqrt(n1)
KI1 <- c(xbar1 - ME1, xbar1 + ME1)
# Variante 2
df2 <- n2 - 1
t_crit2 <- qt(1 - alpha/2, df2)
ME2 <- t_crit2 * s2 / sqrt(n2)
KI2 <- c(xbar2 - ME2, xbar2 + ME2)
KI1
KI2
```
### Visualisierung
```{r}
#| label: fig-aufg2
#| fig-cap: "95%-Konfidenzintervalle der Auslieferungszeit für beide Varianten. Die gestrichelte Linie markiert den aktuellen Mittelwert von 32 Minuten."
#| fig-width: 6
#| fig-height: 4
tibble(
Variante = factor(c("Variante 1", "Variante 2")),
mitte = c(xbar1, xbar2),
untere = c(KI1[1], KI2[1]),
obere = c(KI1[2], KI2[2])
) |>
ggplot(aes(x = Variante, y = mitte)) +
geom_errorbar(aes(ymin = untere, ymax = obere),
width = 0.15, colour = blau, linewidth = 1) +
geom_point(colour = blau, size = 3) +
geom_hline(yintercept = 32, linetype = "dashed",
colour = rot, linewidth = 0.8) +
annotate("text", x = 2.45, y = 32.4,
label = "aktuell: 32 Min.", colour = rot, hjust = 1, size = 3.5) +
labs(x = NULL, y = "Auslieferungszeit [Min.]") +
theme_minimal(base_size = 12)
```
:::
------------------------------------------------------------------------
## Aufgabe 3: Steuergeräte
Eine Firma stellt in Massenproduktion Steuergeräte für die Regeltechnik her.
Unmittelbar nachdem eine neue Produktionsanlage in Betrieb genommen wurde, schätzt ein Kontrolleur mit Hilfe einer Stichprobe die Qualität der neuen Anlage ein.
Dazu entnimmt er 900 Steuergeräte aus der laufenden Produktion und findet 90 Geräte, welche die Spezifikation nicht erfüllen.\
a) Bestimmen Sie das 95%-Konfidenzintervall für den Anteil an Steuergeräten in der Gesamtproduktion der neuen Anlage, welche die Spezifikation nicht erfüllen.\
b) Auf der alten Produktionsanlage erfüllen im Mittel 6% der Steuergeräte die Spezifikationen nicht.
Kann man auf Grund des in a) berechneten Konfidenzintervalls sagen, dass die neue Anlage momentan noch eine schlechtere Qualität liefert als die alte Anlage?
::: {.callout-tip title="Analytische Lösung anzeigen" collapse="true"}
Welches KI bestimmen wir? Wilson oder Wald? Wir prüfen.
Faustregel für die Normalapproximation:
$$n \cdot \hat{p} = 900 \cdot 0.1 = 90 \geq 5 \;\checkmark \qquad
n \cdot (1-\hat{p}) = 900 \cdot 0.9 = 810 \geq 5 \;\checkmark$$
Bei $n = 900$ ist die Approximation der Binomialverteilung durch die Normalverteilung sehr gut — das Wald-Intervall ist hier gerechtfertigt.
Das Wilson-Intervall liefert bei solch grossen Stichproben praktisch dasselbe Ergebnis.
a) 95%-Konfidenzintervall für Anteil $p$
$$\hat{p} = \frac{90}{900} = 0.1$$ $$ SE = \sqrt{\frac{0.1 \cdot 0.9}{900}} = 0.01 $$ $$ z_{0.975} = 1.96 $$ $$ KI = 0.1 \pm 1.96 \cdot 0.01 = [0.08, 0.12] $$
b) Vergleich mit altem Wert $0.06$
Da $0.06$ nicht im Intervall $[0.08, 0.12]$ liegt, ist die Qualität der neuen Anlage **signifikant schlechter**, zumindest zu einem $\alpha = 5\%$.
:::
::: {.callout-tip title="Lösung mit R anzeigen" collapse="true"}
```{r}
n <- 900
p_hat <- 90 / n
z <- qnorm(0.975) # 95%-KI
se_prop <- sqrt(p_hat * (1 - p_hat) / n)
CI_prop <- c(p_hat - z * se_prop, p_hat + z * se_prop)
cat(sprintf("95%%-Konfidenzintervall für den Anteil fehlerhafter Geräte:\n[%.4f, %.4f]",CI_prop[1], CI_prop[2]))
```
:::
## Aufgabe 4: Mehlpackungen
In einer Anlage sollen Pakete zu **1000 g** Mehl abgefüllt werden.\
Eine Stichprobe von $n=20$ Paketen ergab den Mittelwert $\bar{x}=1002\text{ g}$.
a) Erfahrungsgemäss ist die abgepackte Menge **normalverteilt** mit bekannter Standardabweichung $\sigma = 5\text{ g}$.
b) Erfahrungsgemäss ist die abgepackte Menge normalverteilt, die **Standardabweichung der Population ist unbekannt**; in der Stichprobe beträgt sie $s = 5\text{ g}$.
Erstellen Sie in beiden Fällen ein **95 %-Konfidenzintervall** für den wahren mittleren Packungsinhalt und entscheiden Sie, ob die Anlage im Mittel zu viel Mehl abpackt oder ob der beobachtete Mehrinhalt zufällig sein könnte.
::: {.callout-tip title="Analytische Lösung anzeigen" collapse="true"}
**Gegeben:** $\bar{x}=1002\text{ g},\; n=20$
a) $\sigma$ bekannt ($\sigma = 5\text{ g}$)
$$
SE = \frac{\sigma}{\sqrt{n}}
= \frac{5}{\sqrt{20}}
\approx 2.19\text{ g}
$$ $$
\text{95 %-KI} = 1002 \pm 2.19 = [999.81; 1004.19]\text{g}
$$
b) $\sigma$ unbekannt ($s = 5\text{ g}$)
$$
ME = t_{(0,975;~19)}\,\frac{s}{\sqrt{n}}
\approx 2.093 \cdot 1.118
\approx 2.34\text{ g}
$$
$$
\text{95 %-KI} = 1002 \pm 2.34 = [999.66;~1004.34]\text{g}
$$
**Interpretation**
In beiden Varianten liegt das Sollgewicht **1000 g** innerhalb des Intervalls.\
Es gibt daher **keinen signifikanten Hinweis** darauf, dass die Anlage zu viel Mehl dosiert.
Der Mehrinhalt von $2$ g kann zufällig sein.
:::
::: {.callout-tip title="Lösung mit R anzeigen" collapse="true"}
```{r}
# Parameter
n <- 20
xbar <- 1002
sigma <- 5
#für Teil a)
s <- 5 # Stichproben-SD
# für Teil b)
alpha <- 0.05
# Teil a)
# z-Intervall ($\sigma$ bekannt)
z_crit <- qnorm(1 - alpha/2)
moe_z <- z_crit * sigma / sqrt(n)
ci_z <- xbar + c(-moe_z, moe_z)
# Teil b)
# t-Intervall ($sigma$ unbekannt)
t_crit <- qt(1 - alpha/2, df = n - 1)
moe_t <- t_crit * s / sqrt(n)
ci_t <- xbar + c(-moe_t, moe_t)
# Ausgabe (knit‑freundlich)
knitr::kable(
data.frame(
Variante = c("σ bekannt (z)", "σ unbekannt (t)"),
`Untere Grenze` = c(ci_z[1], ci_t[1]),
`Obere Grenze` = c(ci_z[2], ci_t[2]),check.names = FALSE
),
digits = 2,
caption = "95 %-Konfidenzintervalle für das wahre mittlere Packungsgewicht"
)
```
:::
------------------------------------------------------------------------
## Aufgabe 5: App-Absturzrate
Ein Software-Team möchte die Stabilität seiner mobilen Applikation beurteilen.
Dazu wurden in einem Testzeitraum **800 Nutzungssessions** protokolliert.
Bei **42 Sessions** kam es zu einem unerwarteten Absturz der App.
Die Daten liegen als CSV-Datei vor (`app_absturzrate.csv`), wobei die Spalte `absturz` den Wert $1$ für einen Absturz und $0$ für eine fehlerfreie Session enthält.\
a) Berechnen Sie $\hat{p}$ und prüfen Sie, ob die Normalapproximation gültig ist.\
b) Berechnen Sie das **Wald-Intervall** und das **Wilson-Intervall** (je 95%) manuell und mit `prop.test()`.
Vergleichen Sie die Ergebnisse.\
c) Das Team hat als Qualitätsziel eine Absturzrate von maximal **4%** definiert.
Was sagen die KIs über die Erfüllung dieses Ziels aus?
::: {.callout-tip title="Analytische Lösung anzeigen" collapse="true"}
a) **Schätzer und Faustregel**
$$\hat{p} = \frac{42}{800} = 0.0525$$
Faustregel: $n \cdot \hat{p} = 800 \cdot 0.0525 = 42 \geq 5$ ✓ — Normalapproximation gültig.
b) **Wald-Intervall**
$$SE = \sqrt{\frac{0.0525 \cdot 0.9475}{800}} \approx 0.00789$$
$$KI_{\text{Wald}} = 0.0525 \pm 1.96 \cdot 0.00789 = [0.0370,\; 0.0680]$$
**Wilson-Intervall** (mit $z = 1.96$, $n = 800$):
$$\text{Mittelpunkt} = \frac{0.0525 + \frac{1.96^2}{2 \cdot 800}}{1 + \frac{1.96^2}{800}} \approx 0.0527$$
$$KI_{\text{Wilson}} \approx [0.0388,\; 0.0685]$$
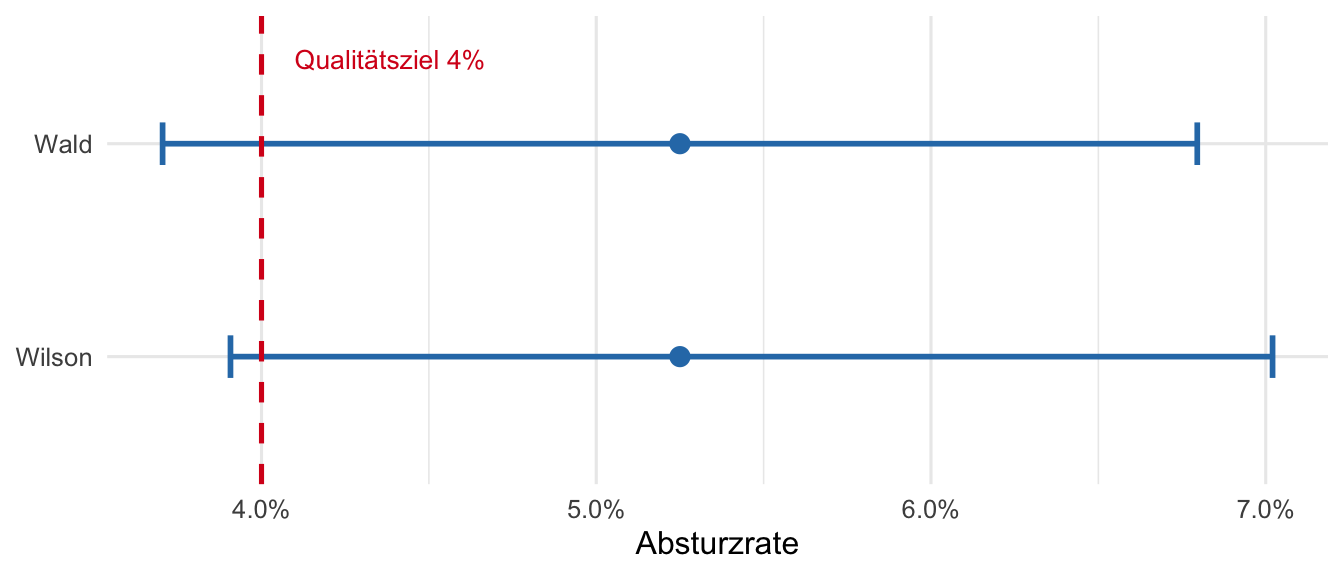
Die Unterschiede sind bei $n = 800$ gering; das Wilson-Intervall liegt minimal weiter rechts, da sein Mittelpunkt leicht über $\hat{p}$ liegt.
c) **Vergleich mit Qualitätsziel 4%**
Das Qualitätsziel $p_0 = 0.04$ liegt bei beiden KIs **ausserhalb** des Intervalls — unterhalb der unteren Grenze ($0.037$ bzw. $0.039$).
Die beobachtete Absturzrate ist statistisch signifikant **höher** als das Ziel.
Das Team sollte Massnahmen einleiten.
:::
::: {.callout-tip title="Lösung mit R anzeigen" collapse="true"}
```{r}
# Daten laden
daten <- read.csv("data/app_absturzrate.csv")
# Kennzahlen
n <- nrow(daten)
x <- sum(daten$absturz)
p_hat <- mean(daten$absturz)
cat("Stichprobenumfang n:", n, "\n")
cat("Abstürze x:", x, "\n")
cat("Schätzer p_hat:", round(p_hat, 4), "\n")
cat("Faustregel n*p_hat:", round(n * p_hat, 1), "\n\n")
# Wald-Intervall (manuell)
z <- qnorm(0.975)
se <- sqrt(p_hat * (1 - p_hat) / n)
wald <- c(p_hat - z * se, p_hat + z * se)
# Wilson-Intervall via prop.test
wilson <- prop.test(x, n, conf.level = 0.95, correct = FALSE)$conf.int
# Vergleich
knitr::kable(
data.frame(
Methode = c("Wald", "Wilson (prop.test)"),
Untergrenze = round(c(wald[1], wilson[1]), 4),
Obergrenze = round(c(wald[2], wilson[2]), 4)
),
caption = "95%-Konfidenzintervalle für die Absturzrate"
)
```
```{r}
#| label: fig-aufg5
#| fig-cap: "95%-KIs für die App-Absturzrate (Wald und Wilson). Die rote Linie markiert das Qualitätsziel von 4%."
#| fig-width: 7
#| fig-height: 3
tibble(
Methode = factor(c("Wald", "Wilson"), levels = c("Wilson", "Wald")),
mitte = p_hat,
untere = c(wald[1], wilson[1]),
obere = c(wald[2], wilson[2])
) |>
ggplot(aes(y = Methode)) +
geom_errorbarh(aes(xmin = untere, xmax = obere),
height = 0.2, colour = blau, linewidth = 1) +
geom_point(aes(x = mitte), colour = blau, size = 3) +
geom_vline(xintercept = 0.04, colour = rot,
linetype = "dashed", linewidth = 0.9) +
annotate("text", x = 0.041, y = 2.4,
label = "Qualitätsziel 4%", colour = rot, hjust = 0, size = 3.5) +
scale_x_continuous(labels = scales::label_percent(accuracy = 0.1)) +
labs(x = "Absturzrate", y = NULL) +
theme_minimal(base_size = 12)
```
:::
------------------------------------------------------------------------
## Aufgabe 6: Produktionsfehler
In einer Kleinserienfertigung werden **30 Bauteile** stichprobenartig geprüft.
Dabei werden **3 Ausschussteile** gefunden.
Die Daten liegen als CSV-Datei vor (`produktionsfehler.csv`), wobei die Spalte `ausschuss` den Wert $1$ für ein fehlerhaftes Bauteil enthält.\
a) Berechnen Sie $\hat{p}$ und prüfen Sie die Faustregel für die Normalapproximation.
Was stellen Sie fest?\
b) Berechnen Sie das 95%-Konfidenzintervall mit dem Wald-Intervall, dem Wilson-Intervall und dem exakten Clopper-Pearson-Intervall (`binom.test()`).
Vergleichen Sie die drei Varianten.\
c) Die Produktion gilt als akzeptabel, wenn die Fehlerquote unter **15%** liegt.
Welche Schlussfolgerung ziehen Sie?
Welcher Methode vertrauen Sie am meisten — und warum?
::: {.callout-tip title="Analytische Lösung anzeigen" collapse="true"}
a. **Schätzer und Faustregel**
$$\hat{p} = \frac{3}{30} = 0.10$$
Faustregel: $n \cdot \hat{p} = 30 \cdot 0.10 = 3.0 < 5 ~ \Rightarrow$ **Normalapproximation nicht zuverlässig!** Das Wald- und das Wilson-Intervall sind bei so kleinen Stichproben und extremen Anteilswerten unzuverlässig.
Das exakte Clopper-Pearson-Intervall ist hier die empfohlene Methode.
b. **Wald-Intervall**
$$SE = \sqrt{\frac{0.10 \cdot 0.90}{30}} \approx 0.0548$$
$$KI_{\text{Wald}} = 0.10 \pm 1.96 \cdot 0.0548 = [-0.007,\; 0.207]$$
Die untere Grenze ist negativ — ein Anteilswert kann nicht negativ sein.
Dies zeigt die Unzuverlässigkeit des Wald-Intervalls bei kleinen Stichproben deutlich.
**Wilson-Intervall** korrigiert dies und liefert $KI_{\text{Wilson}} \approx [0.034,\; 0.254]$ — die untere Grenze ist positiv.
**Clopper-Pearson**: basiert auf der exakten Binomialverteilung, keine Normalapproximation.
$KI_{\text{exakt}} \approx [0.021,\; 0.266]$.
c. **Vergleich mit Grenzwert 15%**
Alle drei KIs enthalten $0.15$.
Es gibt daher **keinen statistischen Beleg**, dass die Fehlerquote über 15% liegt.
Die Daten sind mit einem akzeptablen Prozess vereinbar — allerdings ist bei $n = 30$ die Aussagekraft gering.
Eine grössere Stichprobe ist empfehlenswert.
Das Clopper-Pearson-Intervall ist hier am verlässlichsten, da die Faustregel für Wald und Wilson verletzt ist.
:::
::: {.callout-tip title="Lösung mit R anzeigen" collapse="true"}
```{r}
# Daten laden
daten <- read.csv("data/produktionsfehler.csv")
n <- nrow(daten)
x <- sum(daten$ausschuss)
p_hat <- mean(daten$ausschuss)
cat("n:", n, "| Ausschuss:", x, "| p_hat:", round(p_hat, 4), "\n")
cat("Faustregel n*p_hat =", round(n * p_hat, 1),
ifelse(n * p_hat >= 5, "✓", "✗ VERLETZT – Normalapproximation unzuverlässig"), "\n\n")
# Wald-Intervall (manuell)
z <- qnorm(0.975)
se <- sqrt(p_hat * (1 - p_hat) / n)
wald <- c(p_hat - z * se, p_hat + z * se)
# Wilson-Intervall
wilson <- prop.test(x, n, conf.level = 0.95, correct = FALSE)$conf.int
# Exaktes Clopper-Pearson-Intervall
exakt <- binom.test(x, n, conf.level = 0.95)$conf.int
knitr::kable(
data.frame(
Methode = c("Wald", "Wilson", "Clopper-Pearson (exakt)"),
Untergrenze = round(c(wald[1], wilson[1], exakt[1]), 4),
Obergrenze = round(c(wald[2], wilson[2], exakt[2]), 4)
),
caption = "95%-Konfidenzintervalle für die Fehlerquote (n = 30)"
)
```
:::
------------------------------------------------------------------------
## Aufgabe 7: Kundenzufriedenheit
Ein Onlinehändler hat seine Lieferlogistik verbessert.
Vor der Verbesserung wurden **300 Kunden** befragt; **62 davon** waren mit der Lieferung unzufrieden.
Nach der Verbesserung wurden **280 Kunden** befragt; **54 davon** waren unzufrieden.
Die Daten liegen als CSV-Datei vor (`kundenzufriedenheit.csv`) mit den Spalten `periode` (`vor_Verbesserung` / `nach_Verbesserung`) und `unzufrieden` ($0$/$1$).\
a) Berechnen Sie für beide Perioden je ein 95%-Konfidenzintervall für den Anteil unzufriedener Kunden.\
b) Visualisieren Sie die beiden KIs in einem gemeinsamen Plot.\
c) Überlappen die beiden Intervalle?
Was bedeutet das für die Beurteilung der Wirksamkeit der Massnahme?
Formulieren Sie eine statistisch korrekte Schlussfolgerung.
::: {.callout-tip title="Analytische Lösung anzeigen" collapse="true"}
a) **Periode 1 (vor Verbesserung):** $n_1 = 300$, $x_1 = 62$
$$\hat{p}_1 = \frac{62}{300} \approx 0.207$$
$$SE_1 = \sqrt{\frac{0.207 \cdot 0.793}{300}} \approx 0.0234$$
$$KI_1 = 0.207 \pm 1.96 \cdot 0.0234 = [0.161,\; 0.253]$$
**Periode 2 (nach Verbesserung):** $n_2 = 280$, $x_2 = 54$
$$\hat{p}_2 = \frac{54}{280} \approx 0.193$$
$$SE_2 = \sqrt{\frac{0.193 \cdot 0.807}{280}} \approx 0.0236$$
$$KI_2 = 0.193 \pm 1.96 \cdot 0.0236 = [0.147,\; 0.239]$$
b) Visualisierung: siehe R-Lösung.
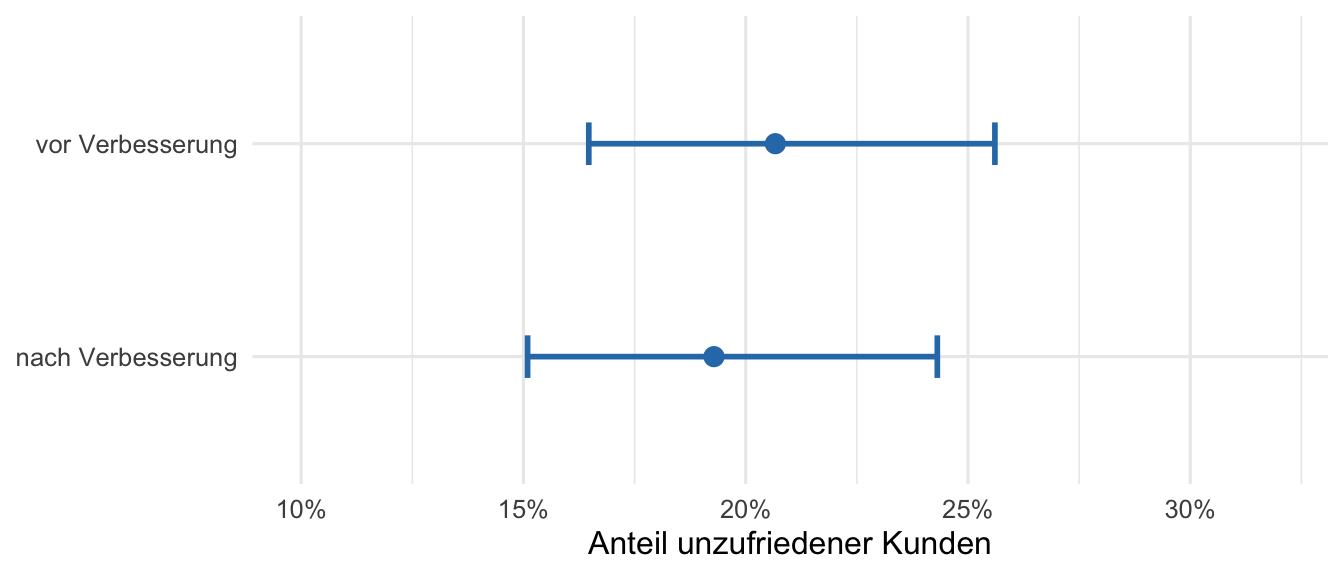
c) **Interpretation**
Die beiden Konfidenzintervalle überlappen stark.
Die Unzufriedenheitsrate hat sich von $\hat{p}_1 \approx 20.7\%$ auf $\hat{p}_2 \approx 19.3\%$ leicht reduziert — dieser Unterschied ist aber statistisch **nicht belegt**.
Beide Werte liegen komfortabel im KI der jeweils anderen Periode.
Es besteht kein statistischer Beleg dafür, dass die Massnahme die Unzufriedenheitsrate gesenkt hat.
Für eine gesicherte Aussage wären grössere Stichproben oder ein formaler Zwei-Stichproben-Test notwendig.
:::
::: {.callout-tip title="Lösung mit R anzeigen" collapse="true"}
```{r}
# Daten laden
daten <- read.csv("data/kundenzufriedenheit.csv")
# Aufteilen nach Periode
vor <- daten[daten$periode == "vor_Verbesserung", "unzufrieden"]
nach <- daten[daten$periode == "nach_Verbesserung", "unzufrieden"]
# KIs mit prop.test (Wilson)
ki_vor <- prop.test(sum(vor), length(vor), conf.level = 0.95, correct = FALSE)
ki_nach <- prop.test(sum(nach), length(nach), conf.level = 0.95, correct = FALSE)
knitr::kable(
data.frame(
Periode = c("vor Verbesserung", "nach Verbesserung"),
n = c(length(vor), length(nach)),
Unzufrieden = c(sum(vor), sum(nach)),
p_hat = round(c(ki_vor$estimate, ki_nach$estimate), 4),
Untergrenze = round(c(ki_vor$conf.int[1], ki_nach$conf.int[1]), 4),
Obergrenze = round(c(ki_vor$conf.int[2], ki_nach$conf.int[2]), 4)
),
caption = "95%-KIs für den Anteil unzufriedener Kunden"
)
```
```{r}
#| label: fig-aufg7
#| fig-cap: "95%-KIs für den Anteil unzufriedener Kunden vor und nach der Verbesserung."
#| fig-width: 7
#| fig-height: 3
tibble(
Periode = factor(c("vor Verbesserung", "nach Verbesserung"),
levels = c("nach Verbesserung", "vor Verbesserung")),
mitte = c(ki_vor$estimate, ki_nach$estimate),
untere = c(ki_vor$conf.int[1], ki_nach$conf.int[1]),
obere = c(ki_vor$conf.int[2], ki_nach$conf.int[2])
) |>
ggplot(aes(y = Periode)) +
geom_errorbarh(aes(xmin = untere, xmax = obere),
height = 0.2, colour = blau, linewidth = 1) +
geom_point(aes(x = mitte), colour = blau, size = 3) +
scale_x_continuous(labels = scales::label_percent(accuracy = 1),
limits = c(0.10, 0.32)) +
labs(x = "Anteil unzufriedener Kunden", y = NULL) +
theme_minimal(base_size = 12)
```
:::
------------------------------------------------------------------------
## Aufgabe 8: Serverausfälle und SLA
Ein Rechenzentrum überwacht die Verfügbarkeit eines Servers über **500 Stunden**.
In **21 Stunden** war der Server nicht erreichbar.
Die Daten liegen als CSV-Datei vor (`serverausfall.csv`), wobei die Spalte `ausfall` den Wert $1$ für eine Ausfallstunde enthält.\
a) Berechnen Sie das 95%-Konfidenzintervall für die Ausfallrate.\
b) Berechnen Sie zusätzlich das 90%- und das 99%-Konfidenzintervall.
Stellen Sie alle drei in einer Tabelle und einem Plot gegenüber.\
c) Im Service-Level-Agreement (SLA) ist eine maximale Ausfallrate von **4%** vereinbart.
Beurteilen Sie anhand der drei KIs, ob der Server die SLA erfüllt — und wie sich das Ergebnis mit dem Konfidenzniveau verändert.
::: {.callout-tip title="Analytische Lösung anzeigen" collapse="true"}
a) **Schätzer und 95%-KI**
$$\hat{p} = \frac{21}{500} = 0.042$$
$$SE = \sqrt{\frac{0.042 \cdot 0.958}{500}} \approx 0.00897$$
$$KI_{95\%} = 0.042 \pm 1.96 \cdot 0.00897 = [0.0244,\; 0.0596]$$
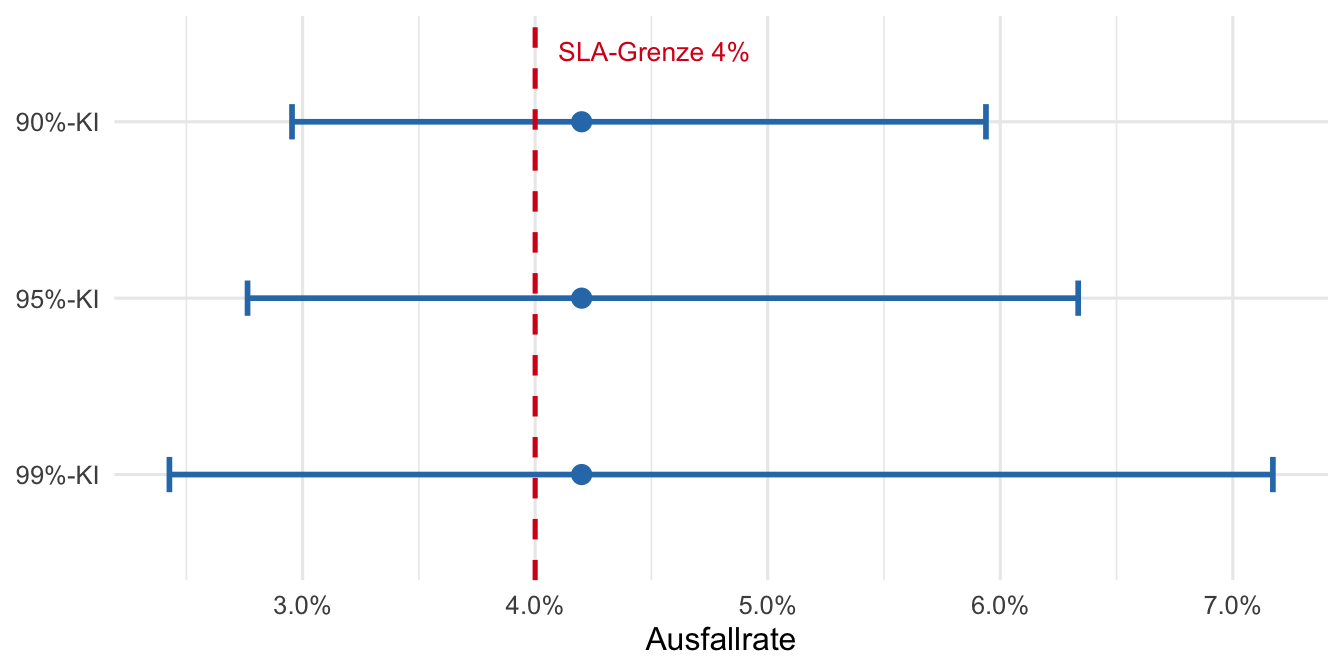
b) **Übersicht aller drei KIs**
| Niveau | $z$ | Untergrenze | Obergrenze |
|--------|-------|-------------|------------|
| 90% | 1.645 | 0.0272 | 0.0568 |
| 95% | 1.960 | 0.0244 | 0.0596 |
| 99% | 2.576 | 0.0189 | 0.0651 |
Mit steigendem Konfidenzniveau wird das Intervall breiter — die grössere Sicherheit erkauft man sich durch weniger Präzision.
c) **SLA-Beurteilung (Grenzwert 4%)**
Der SLA-Wert $p_0 = 0.04$ liegt **innerhalb** aller drei KIs.
Es gibt daher keinen statistischen Beleg auf keinem der drei Niveaus, dass die Ausfallrate die SLA verletzt.
Gleichzeitig schliesst das 99%-KI Ausfallraten bis zu $6.5\%$ ein — der Server bewegt sich im Grenzbereich.
Bei einem niedrigeren Konfidenzniveau (90%) ist das Intervall enger, der SLA-Wert liegt aber immer noch darin.
Mehr Daten würden die Aussagekraft erhöhen.
:::
::: {.callout-tip title="Lösung mit R anzeigen" collapse="true"}
```{r}
# Daten laden
daten <- read.csv("data/serverausfall.csv")
n <- nrow(daten)
x <- sum(daten$ausfall)
p_hat <- mean(daten$ausfall)
cat("n:", n, "| Ausfälle:", x, "| p_hat:", round(p_hat, 4), "\n")
# KIs für drei Niveaus mit prop.test
niveaus <- c(0.90, 0.95, 0.99)
ergebnisse <- lapply(niveaus, function(cl) {
ki <- prop.test(x, n, conf.level = cl, correct = FALSE)$conf.int
data.frame(Niveau = paste0(cl*100, "%"),
Untergrenze = round(ki[1], 4),
Obergrenze = round(ki[2], 4))
})
tab <- do.call(rbind, ergebnisse)
knitr::kable(tab, caption = "KIs für die Ausfallrate bei verschiedenen Konfidenzniveaus")
```
```{r}
#| label: fig-aufg8
#| fig-cap: "KIs für die Serverausfallrate bei 90%, 95% und 99% Konfidenzniveau. Die rote Linie markiert die SLA-Grenze von 4%."
#| fig-width: 7
#| fig-height: 3.5
ki_df <- map_dfr(niveaus, \(cl) {
ki <- prop.test(x, n, conf.level = cl, correct = FALSE)$conf.int
tibble(Niveau = paste0(cl * 100, "%-KI"), mitte = p_hat,
untere = ki[1], obere = ki[2])
}) |>
mutate(Niveau = factor(Niveau, levels = rev(paste0(niveaus * 100, "%-KI"))))
ggplot(ki_df, aes(y = Niveau)) +
geom_errorbarh(aes(xmin = untere, xmax = obere),
height = 0.2, colour = blau, linewidth = 1) +
geom_point(aes(x = mitte), colour = blau, size = 3) +
geom_vline(xintercept = 0.04, colour = rot,
linetype = "dashed", linewidth = 0.9) +
annotate("text", x = 0.041, y = 3.4,
label = "SLA-Grenze 4%", colour = rot, hjust = 0, size = 3.5) +
scale_x_continuous(labels = scales::label_percent(accuracy = 0.1)) +
labs(x = "Ausfallrate", y = NULL) +
theme_minimal(base_size = 12)
```
:::
## Aufgabe 9: Stichprobenplanung – Nebenwirkungsrate
Ein Spital möchte den Anteil $p$ der Patientinnen und Patienten schätzen,
die nach einer neuen Behandlung eine Nebenwirkung zeigen.
Das Ziel ist ein **95%-Konfidenzintervall mit einer Fehlertoleranz von höchstens $\pm 3\%$**
(d.h. die Halbbreite des KI soll $E = 0.03$ nicht überschreiten).\
a) Wie gross muss die Stichprobe mindestens sein, wenn **keinerlei Vorinformation** über $p$ vorliegt?\
b) Eine Vorstudie ergab eine Nebenwirkungsrate von $\hat{p}_0 = 0.12$.
Wie ändert sich der Mindestumfang?\
c) Das Spital möchte die Sicherheit auf **99%** erhöhen (weiterhin $E = 0.03$, konservativer Ansatz).
Wie viele Patientinnen und Patienten sind nun nötig, und was schlussfolgern Sie über
den Zusammenhang zwischen Konfidenzniveau und Stichprobenumfang?
::: {.callout-tip title="Analytische Lösung anzeigen" collapse="true"}
**Vorüberlegung**
Hier haben wir eine andere Ausgangslage als bei bekanntem n.
Die Faustregel $n \cdot p \geq 5$ und $n \cdot (1-p) \geq 5$ kann vor der Berechnung noch nicht geprüft werden — $n$ ist ja noch unbekannt.
Man geht daher so vor:
1. $n$ mit der Formel berechnen und aufrunden.
2. Faustregel im Nachhinein prüfen.
In der Praxis der Stichprobenplanung ist dieser Check jedoch fast immer eine
Formalität: Jedes sinnvoll geplante $n$ (typisch $\geq 30$, oft $\gg 100$) erfüllt
die Bedingung, solange $p$ nicht extrem nahe bei 0 oder 1 liegt.
Für extreme Anteilswerte ($p < 0.05$ oder $p > 0.95$) wäre Wilson oder
Clopper-Pearson die robustere Wahl — die Planungsformel selbst bleibt aber
dieselbe, da sie nur auf der Halbbreite des KI basiert.
Das Wald-KI für $p$ lautet:
$$\hat{p} \;\pm\; z_{1-\alpha/2} \cdot \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}$$
Die Halbbreite — also die maximale Abweichung zwischen Schätzwert und wahrer
Grenze — nennen wir **Fehlertoleranz** $E$:
$$E \;=\; z_{1-\alpha/2} \cdot \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}$$
Wir wollen $E$ **klein genug** halten. Wir stellen also nach $n$ um — zuerst
quadrieren wir beide Seiten:
$$E^2 \;=\; z_{1-\alpha/2}^2 \cdot \frac{\hat{p}(1-\hat{p})}{n}$$
dann $n$ freistellen:
$$n \;=\; \frac{z_{1-\alpha/2}^2 \cdot \hat{p}(1-\hat{p})}{E^2}$$
Da $n$ ganzzahlig sein muss und wir $E$ **nicht überschreiten** dürfen,
wird aufgerundet:
$$n \;\geq\; \left\lceil \frac{z_{1-\alpha/2}^2 \cdot \hat{p}(1-\hat{p})}{E^2} \right\rceil$$
**Das Problem:** $\hat{p}$ ist unbekannt — es ist ja genau das, was wir erst
schätzen wollen. Zwei Auswege:
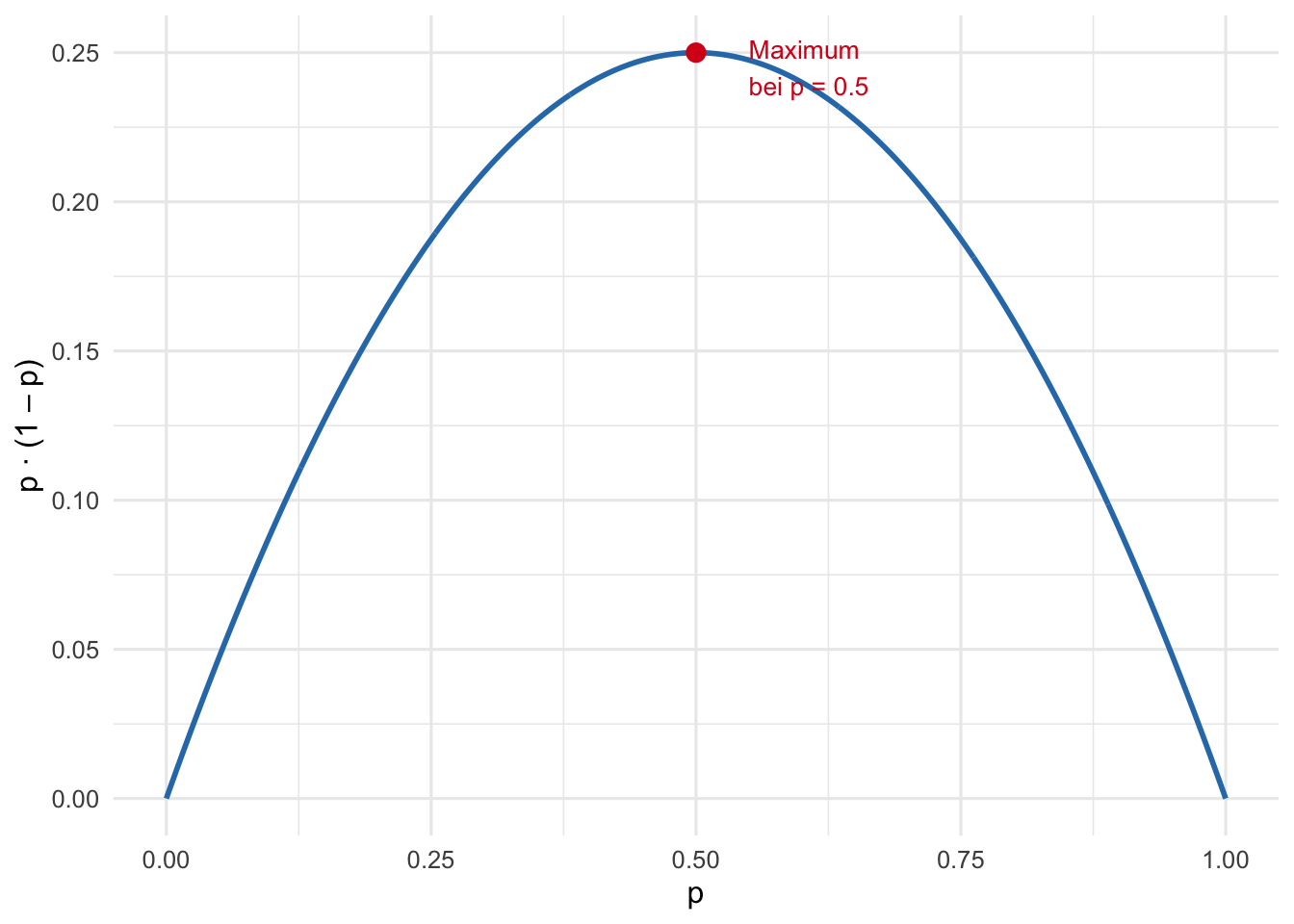
- **Konservativ:** Da $\hat{p}(1-\hat{p})$ bei $\hat{p} = 0.5$ sein Maximum $0.25$
annimmt (siehe Abbildung), liefert $\hat{p} = 0.5$ das **grösste** $n$ —
unabhängig vom wahren $p$ ist man damit auf der sicheren Seite.
- **Mit Vorinformation:** Liegt ein Schätzwert $\hat{p}_0$ aus einer Vorstudie vor,
setzt man diesen ein und erhält ein sparsameres $n$.
```{r}
#| label: fig-pq
#| fig-cap: "p(1-p) als Funktion von p — Maximum bei p = 0.5."
tibble(p = seq(0, 1, by = 0.001), pq = p * (1 - p)) |>
ggplot(aes(x = p, y = pq)) +
geom_line(colour = blau, linewidth = 1) +
annotate("point", x = 0.5, y = 0.25, colour = rot, size = 3) +
annotate("text", x = 0.55, y = 0.245,
label = "Maximum\nbei p = 0.5", colour = rot, hjust = 0, size = 3.5) +
labs(x = "p", y = "p · (1 – p)") +
theme_minimal(base_size = 12)
```
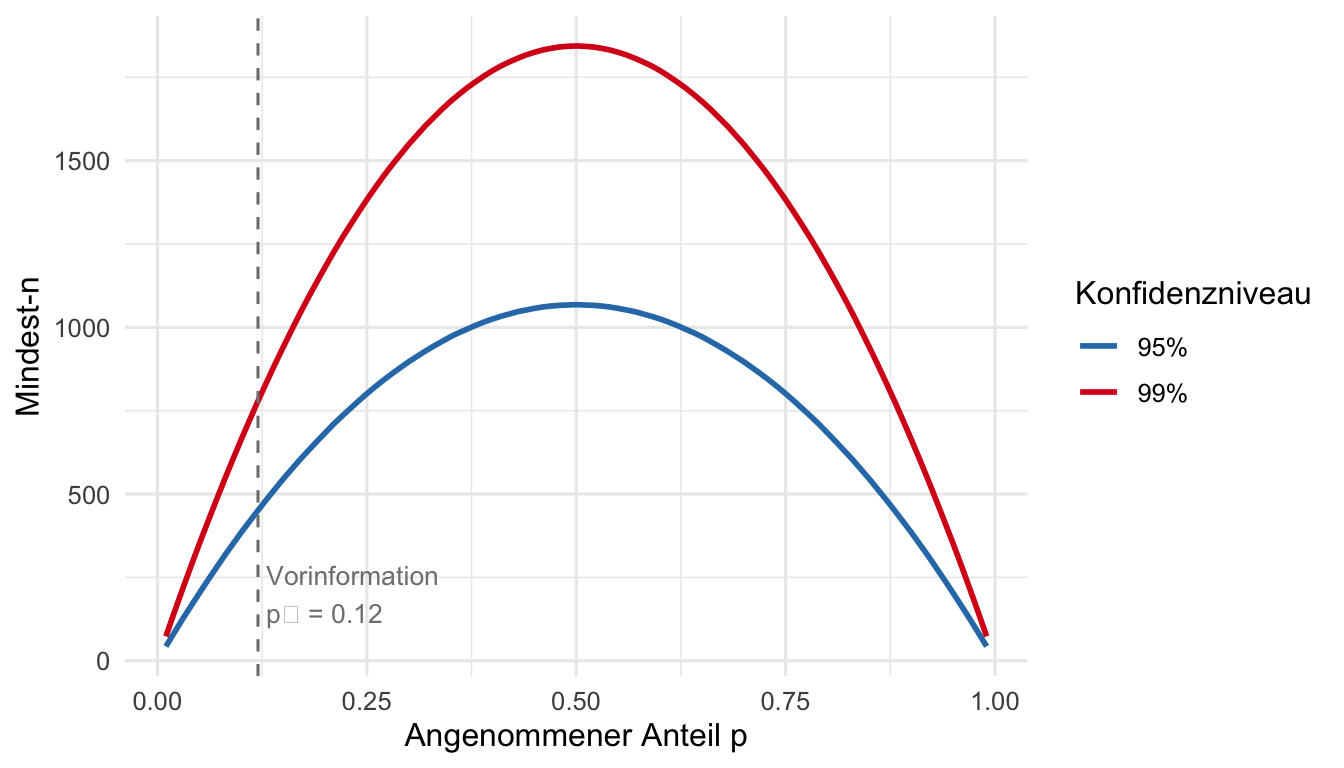
a) **Konservativer Ansatz** ($p = 0.5$ maximiert $p(1-p)$)
$$n \;\geq\; \frac{1.96^2 \cdot 0.5 \cdot 0.5}{0.03^2}
= \frac{3.8416 \cdot 0.25}{0.0009}
= \frac{0.9604}{0.0009}
\approx 1067.1$$
$$\Rightarrow \quad n_{\min} = 1068$$
b) **Mit Vorinformation** $\hat{p}_0 = 0.12$
$$n \;\geq\; \frac{1.96^2 \cdot 0.12 \cdot 0.88}{0.03^2}
= \frac{3.8416 \cdot 0.1056}{0.0009}
\approx 450.6$$
$$\Rightarrow \quad n_{\min} = 451$$
Durch die Vorinformation reduziert sich der Aufwand von 1068 auf 451 Beobachtungen —
eine Einsparung von mehr als 57 %, weil $p = 0.12$ weit vom Maximum $p = 0.5$ entfernt ist.
c) **99%-Niveau**, konservativer Ansatz ($z_{0.995} \approx 2.576$)
$$n \;\geq\; \frac{2.576^2 \cdot 0.5 \cdot 0.5}{0.03^2}
= \frac{6.635 \cdot 0.25}{0.0009}
\approx 1843.3$$
$$\Rightarrow \quad n_{\min} = 1844$$
Ein höheres Konfidenzniveau erfordert einen **grösseren** Stichprobenumfang —
die grössere Sicherheit wird durch mehr Messaufwand erkauft.
Der Umfang skaliert quadratisch mit $z$: von 95% auf 99% steigt $n$ um ca. $73\%$!
:::
::: {.callout-tip title="Lösung mit R anzeigen" collapse="true"}
```{r}
E <- 0.03 # gewünschte Fehlertoleranz (Halbbreite)
# a) Konservativ (p = 0.5), 95%-KI
z95 <- qnorm(0.975)
n_konservativ <- ceiling(z95^2 * 0.5 * 0.5 / E^2)
# b) Mit Vorinformation p0 = 0.12, 95%-KI
p0 <- 0.12
n_vorinformation <- ceiling(z95^2 * p0 * (1 - p0) / E^2)
# c) Konservativ, 99%-KI
z99 <- qnorm(0.995)
n_99 <- ceiling(z99^2 * 0.5 * 0.5 / E^2)
knitr::kable(
data.frame(
Szenario = c("95%-KI, konservativ (p = 0.5)",
"95%-KI, Vorinformation (p = 0.12)",
"99%-KI, konservativ (p = 0.5)"),
z_Wert = round(c(z95, z95, z99), 3),
p_angenommen = c(0.5, 0.12, 0.5),
n_mindest = c(n_konservativ, n_vorinformation, n_99)
),
caption = "Mindest-Stichprobenumfang für E = ±3%"
)
```
```{r}
#| label: fig-aufg9
#| fig-cap: "Benötigter Stichprobenumfang in Abhängigkeit von p, für E = 3% und zwei Konfidenzniveaus."
#| fig-width: 7
#| fig-height: 4
p_seq <- seq(0.01, 0.99, by = 0.01)
tibble(
p = rep(p_seq, 2),
niveau = rep(c("95%", "99%"), each = length(p_seq)),
z = ifelse(niveau == "95%", qnorm(0.975), qnorm(0.995)),
n = ceiling(z^2 * p * (1 - p) / E^2)
) |>
ggplot(aes(x = p, y = n, colour = niveau)) +
geom_line(linewidth = 1) +
geom_vline(xintercept = 0.12, linetype = "dashed", colour = grau) +
annotate("text", x = 0.13, y = 200,
label = "Vorinformation\np₀ = 0.12", hjust = 0, size = 3.5, colour = grau) +
scale_colour_manual(values = c("95%" = blau, "99%" = rot)) +
labs(x = "Angenommener Anteil p", y = "Mindest-n",
colour = "Konfidenzniveau") +
theme_minimal(base_size = 12)
```
:::